分布式集群使用教程
分布式集群配置说明
配额
每个用户默认的集群数量配额为1个,每个集群实例配额为5个(一个集群内最多添加5台机器),如需更多,请联系小助手。

集群类型
基础集群
**功能特性:**支持集群内网络互通。
注:
-
集群中添加 Windows 实例(带Windows图标机器)节点,如果要网络互通,需要打开防火墙;
-
Docker 实例 (带HC图标机器)暂不支持加入集群。
深度学习集群
**功能特性:**支持构建 Tensorflow、Pytorch、Horovod 等用于深度学习分布式训练的集群。
每个集群可配置一个 master 节点,设置 master 节点后,系统将对节点进行重新配置:
- 所有节点注册网卡通信相关环境变量:NCCL_SOCKET_IFNAME、GLOO_IFACE
- 配置 master 节点到其它节点的SSH公钥登录。如果您在配置master节点前,如果已经登录了节点,则设置完成后,需要重新登录该节点才能让配置生效或使用
source ~/.bashrc命令更新环境变量
注:
-
当前仅支持从基础集群升级到深度学习集群,不支持降级;
-
深度学习集群不支持Windows 实例(带Windows图标机器)节点。
GPU 分布式使用教程之 Pytorch
Pytorch 官方推荐使用 DistributedDataParallel(DDP) 模块来实现单机多卡和多机多卡分布式计算。DDP 模块涉及了一些新概念,如网络(World Size/Local Rank),代码修改(数据分配加载),多种启动方式(torchrun/launch),使用前请参考官方文档以及更多学习资料。
选择机器
-
单机多卡分布式:租用同个计算节点的多张卡即可。
-
多机多卡分布式: 点击直达分布式集群,在租用时,请选择带有如图所示图标的机器。没有这个图标的机器不支持加入分布式网络。
![]()
单机多卡
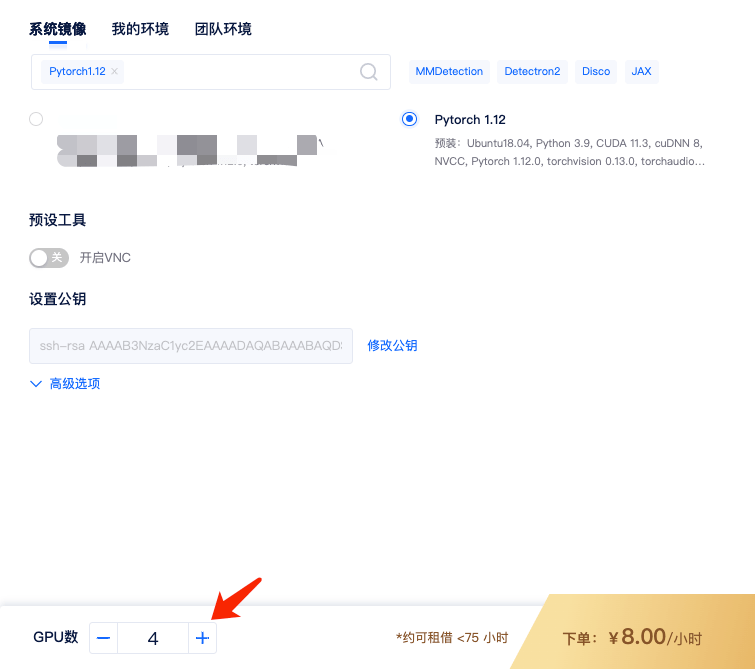
1)租用机器: 为实现 Pytorch 的单机多卡分布式,首先,您需要按正常流程租用GPU,如单节点 4 卡 A2000,选择 Pytorch 镜像,如Pytorch 1.12镜像。
租用的时候 GPU 数设置成 4,即表示 4 卡,对应显存、内存等配置也会翻倍。
2)适配代码: 分布式需对脚本进行相应修改,可参考官方文档。此处使用开源项目作为测试demo,点击下载测试代码mnmc_ddp_launch.py
3)运行代码: 进入运行脚本所在目录,输入命令行,如:
bash复制代码# 项目地址 https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/mnmc_ddp_launch.py # 进入项目目录 cd /mnt/test/multi-card/torch # 复制数据集到当前目录 cp -r /public/torchvision_datasets/cifar-10-batches-py ./ # 运行程序 python -m torch.distributed.launch --nproc_per_node=4 mnmc_ddp_launch.py
这里使用的是 launch 启动方式,也可使用torchrun以及其他启动方式。--nproc_per_node 指定每个节点的GPU数量,mnmc_ddp_launch.py 为执行脚本文件(如需下载 cifar10 数据集,修改download=True)。
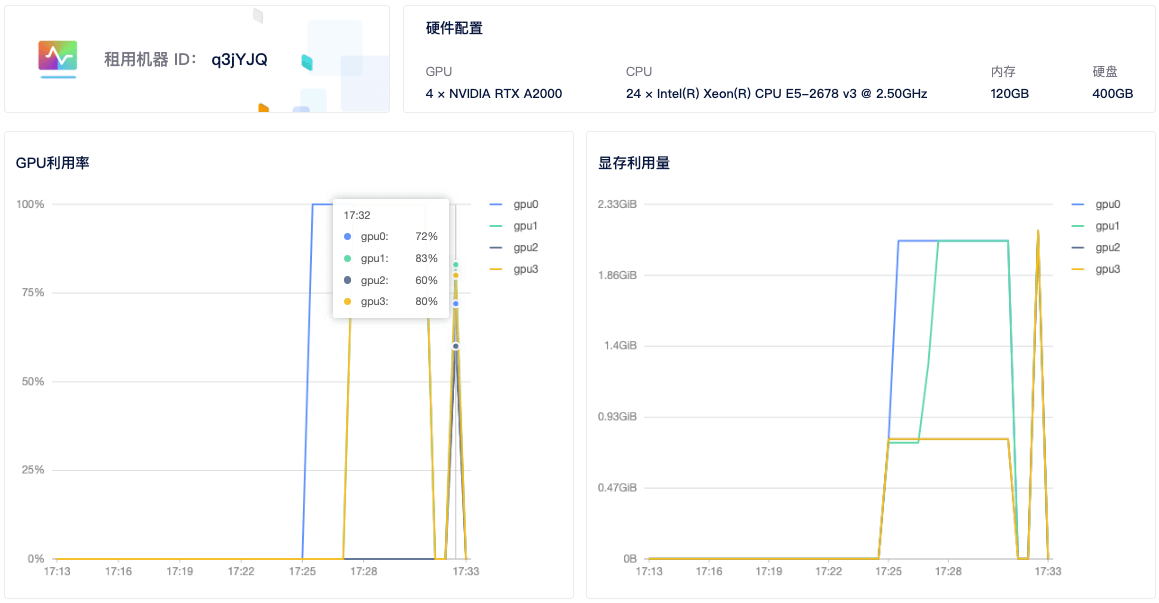
4)查看GPU使用情况: 租用界面点击详情按钮即可查看 GPU、CPU使用情况。从截图中可以看到 4 个显卡都有使用到。
多机多卡
多机多卡需要使用 分布式集群 功能。
1)租用机器: 首先,您需要按正常流程租用 GPU,主机市场筛选栏选择 支持分布式集群 筛选,然后选择自己需要的机器租用即可。
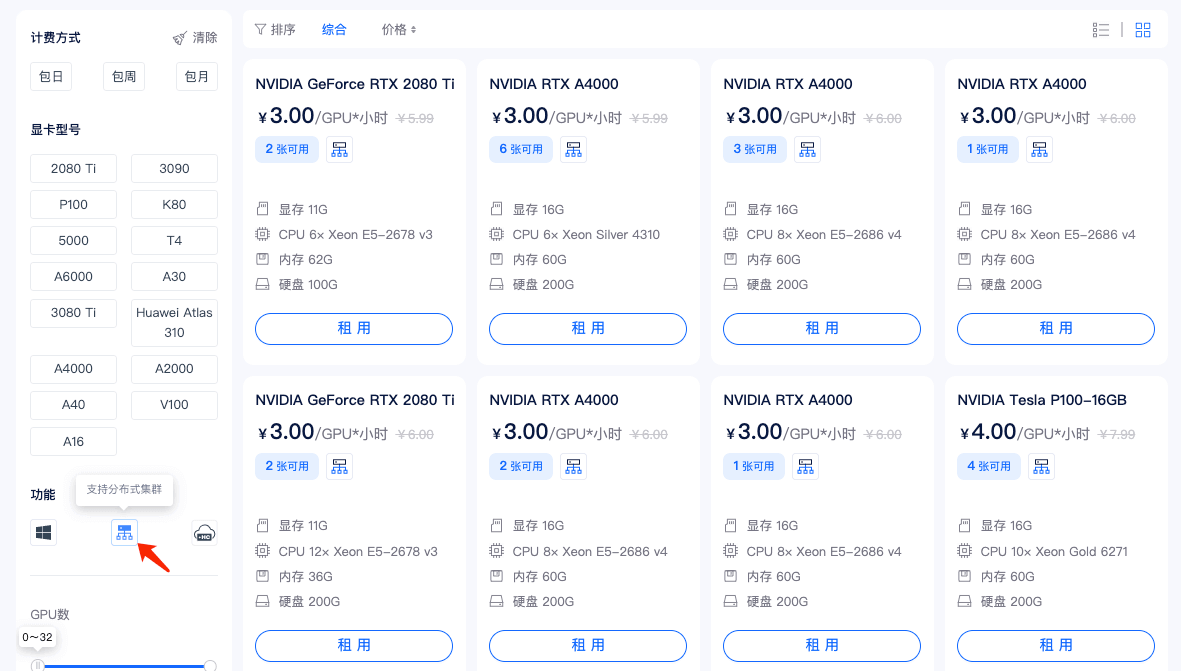
如两个计算节点,租用两台 A2000 4 卡,共计 8 卡。选择相同的Pytorch镜像,如Pytorch 1.12。
注意: 多机多卡中每个节点的 GPU 卡数应该一样,才能都使用上,机器类型也最好一样。
2)创建集群: 进入 【个人中心】 — 【我的租用】 — 【分布式集群】。
点击【添加集群】可以创建一个集群。如果你和我一样,主要用来跑深度学习项目,可以将集群免费升级为深度学习集群。点击这里查看相关说明
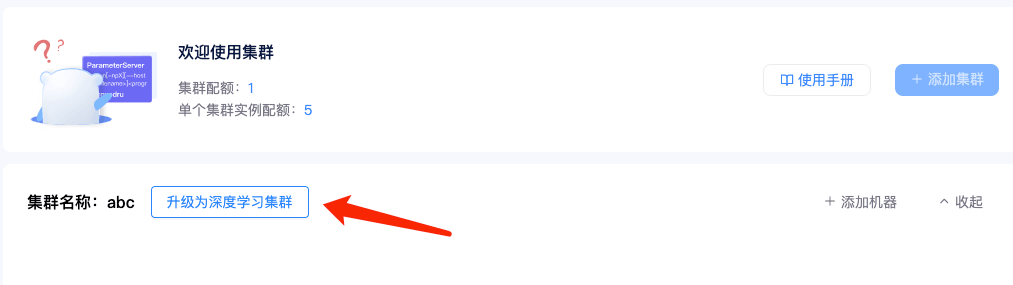
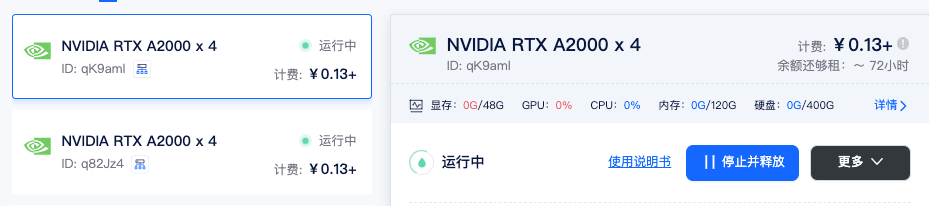
3)添加机器: 点击集群页面添加机器按钮,勾选要加入集群的机器,点击确定,即可将租用机器添加到集群。
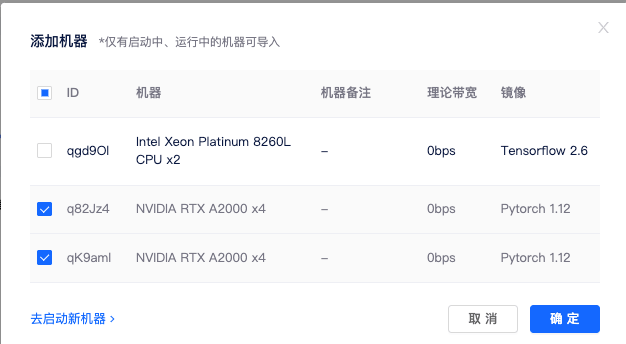
添加机器成功后,系统会给每个节点分配集群 IP,当状态为已连接时,代表机器间可相互通信。这里我们还需要设置一个 master 节点,设置后会自动进行以下操作:
- 所有节点注册网卡的环境变量:NCCL_SOCKET_IFNAME、GLOO_IFACE
- 配置 master 节点到其它节点的SSH公钥登录

4)适配代码: 分布式需对脚本进行相应修改,可参考官方文档。此处使用开源项目作为测试demo,点击下载测试代码mnmc_ddp_launch.py
5)运行程序: 登录 master 节点,进入运行脚本所在目录,输入命令行,如:
bash复制代码# 项目地址 https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/mnmc_ddp_launch.py # 进入项目目录 cd /mnt/test/multi-card/torch # 复制数据集到当前目录 cp -r /public/torchvision_datasets/cifar-10-batches-py ./ # 运行程序 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr="192.168.1.9" --master_port=12345 mnmc_ddp_launch.py
--nproc_per_node 指定每个节点的GPU数量,每个节点GPU数量应该一样,不然无法运行成功,--nnodes 指定节点数(总共2个节点),--node_rank 指定节点顺序(主节点故为0号),--master_addr和master_port 设定主节点ip和端口号。mnmc_ddp_launch.py 为执行脚本。
登录剩余节点,运行:
bash复制代码# 进入项目目录 cd /mnt/test/multi-card/torch # 运行程序 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=1 --master_addr="192.168.1.9" --master_port=12345 mnmc_ddp_launch.py
其中,--node_rank 指定节点顺序(第二个节点故为1号),如有更多节点,需做相应修改,其他参数不用修改。运行后,系统会自动连接并运行训练任务。
6)查看GPU使用情况: 租用界面点击详情按钮即可查看 GPU、CPU使用情况。
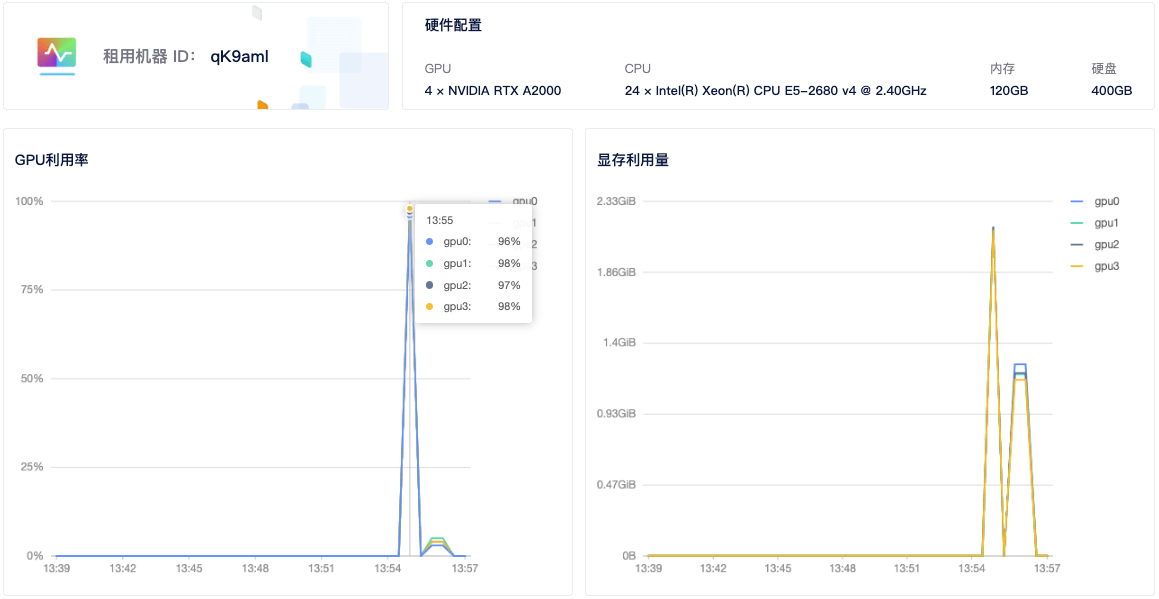

GPU 分布式使用教程之 TensorFlow
TensorFlow 提供了6种策略实现分布式计算,各个策略详情请参考官方文档。本文档使用 MirroredStrategy 实现单机多卡分布式,MultiWorkerMirroredStrategy 实现多机多卡分布式计算。
选择机器
- 单机多卡分布式:租用同个计算节点的多张卡即可。
- 多机多卡分布式: 点击直达分布式集群,在租用时,请选择带有如图所示图标的机器。没有这个图标的机器不支持加入分布式网络。
![]()
单机多卡
1)租用机器: 为实现TensorFlow的单机多卡分布式,首先,您需要按正常流程租用GPU,如单节点 4 卡 A2000,选择TensorFlow镜像,如TensorFlow2.8镜像。
租用的时候 GPU 数设置成 4,即表示 4 卡,对应显存、内存等配置也会翻倍。
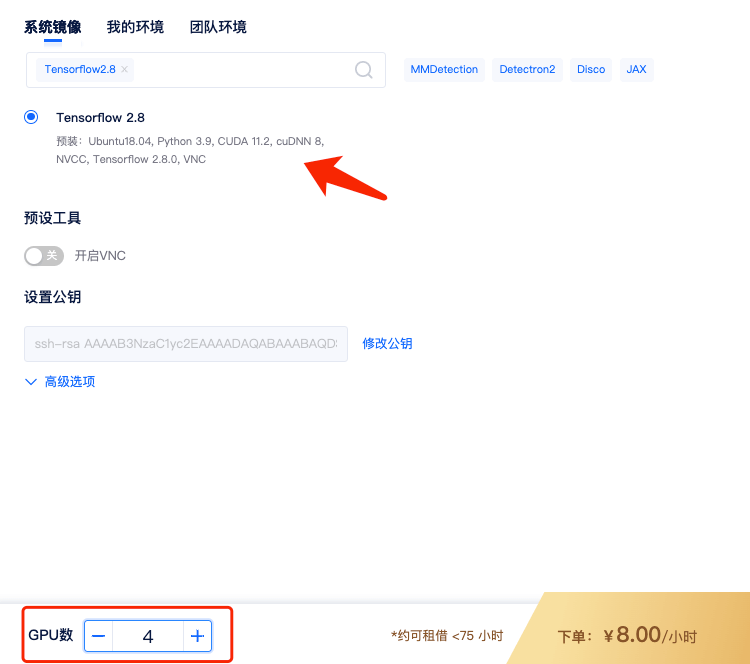
2)适配代码: 单机多卡分布式使用 MirroredStrategy 需对脚本进行相应修改,点击下载测试代码(将代码写入机器中的一个 .py 文件即可,如:tf-demo.py )。
3)运行代码: 进入运行脚本所在目录,输入命令行,如:
bash复制代码# 进入脚本目录 cd /mnt/test/multi-card/tf # 解压数据集到当前目录 unzip /public/tensorflow_datasets/cats_vs_dogs/kagglecatsanddogs_3367a.zip -d ./cats_vs_dogs # 安装缺的依赖包 pip install tensorflow_datasets # 运行程序 python tf-demo.py
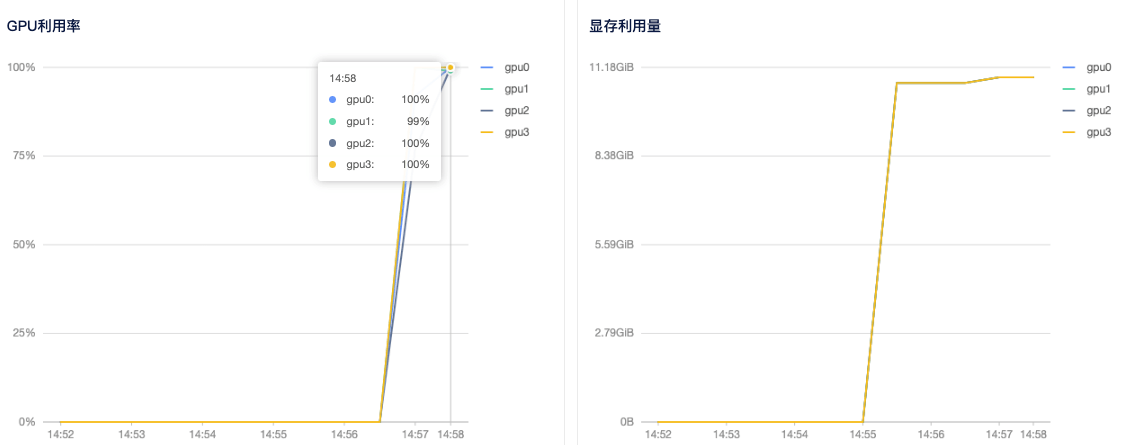
4)查看GPU使用情况: 租用界面点击详情按钮即可查看 GPU、CPU使用情况。从截图中可以看到 4 个显卡都有使用到。
多机多卡
多机多卡需要使用 分布式集群 功能。
1)租用机器: 首先,您需要按正常流程租用 GPU,主机市场筛选栏选择 支持分布式集群 筛选,然后选择自己需要的机器租用即可。
如两个计算节点,租用两台 A2000 4,共计 8 卡。选择相同的 TensorFlow 镜像,如 TensorFlow2.8 镜像。

注意: 多机多卡中每个节点的 GPU 卡数应该一样,才能都使用上,机器类型也最好一样。
2)创建集群: 进入 【个人中心】 — 【我的租用】 — 【分布式集群】。
点击【添加集群】可以创建一个集群。如果你和我一样,主要用来跑深度学习项目,可以将集群免费升级为深度学习集群。点击这里查看相关说明
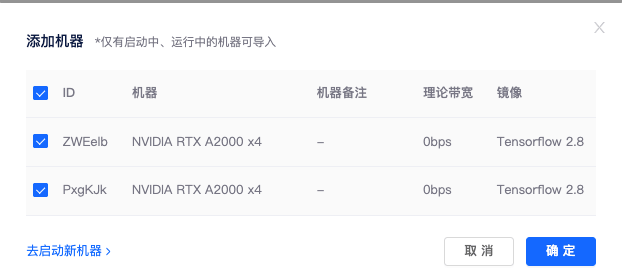
3)添加机器: 点击集群页面添加机器按钮,勾选要加入集群的机器,点击确定,即可将租用机器添加到集群。
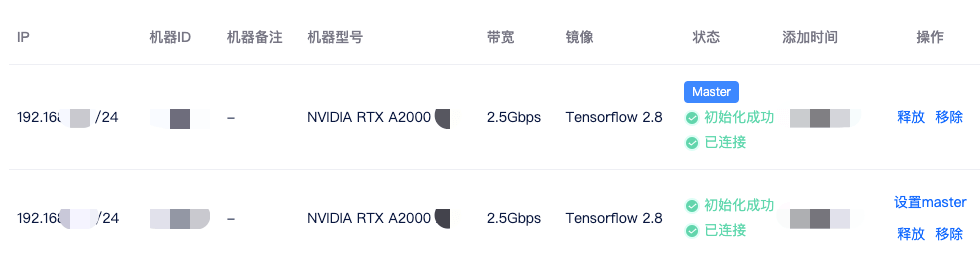
添加机器成功后,系统会给每个节点分配集群 IP,当状态为已连接时,代表机器间可相互通信。这里我们还需要设置一个 master 节点,设置后会自动:
- 所有节点注册网卡的环境变量:NCCL_SOCKET_IFNAME、GLOO_IFACE
- 配置 master 节点到其它节点的SSH公钥登录
4)适配代码: 注意和单机多卡不同,多机多卡使用了 MultiWorkerMirroredStrategy,并需要配置TF_CONFIG网络设置:
python复制代码os.environ['TF_CONFIG'] = json.dumps({ 'cluster': { 'worker': ["192.168.1.7:20005", "192.168.1.8:20006"] }, 'task': {'type': 'worker', 'index':0} })
其中 cluster 包含了全部节点的IP和端口信息,所有节点此部分相同;task包含当前节点的角色,例如节点一为worker 0,节点二为worker 1。
点击下载测试代码(将代码写入机器中的一个 .py 文件即可,如:tf-demo2.py ):
5)运行程序: 登录主节点,进入运行脚本所在目录,输入命令行,如:
bash复制代码# 进入脚本目录 cd /mnt/test/multi-card/tf # 解压数据集到当前目录 unzip /public/tensorflow_datasets/cats_vs_dogs/kagglecatsanddogs_3367a.zip -d ./cats_vs_dogs # 安装缺的依赖包 pip install tensorflow_datasets # 运行程序 python tf-demo2.py --num_workers 2 --worker_no 0
测试代码中,--num_workers 指定节点数(总共2个节点),用于设定batch_size, --worker_no 指定节点顺序(主节点故为0号)。
登录剩余节点,运行:
bash复制代码# 进入脚本目录 cd /mnt/test/multi-card/tf # 安装缺的依赖包 pip install tensorflow_datasets # 运行程序 python tf-demo2.py --num_workers 2 --worker_no 1
其中,--worker_no 指定节点顺序(第二个节点故为1号),如有更多节点,需做相应修改,其他参数不用修改。运行后,系统会自动连接并运行训练任务。
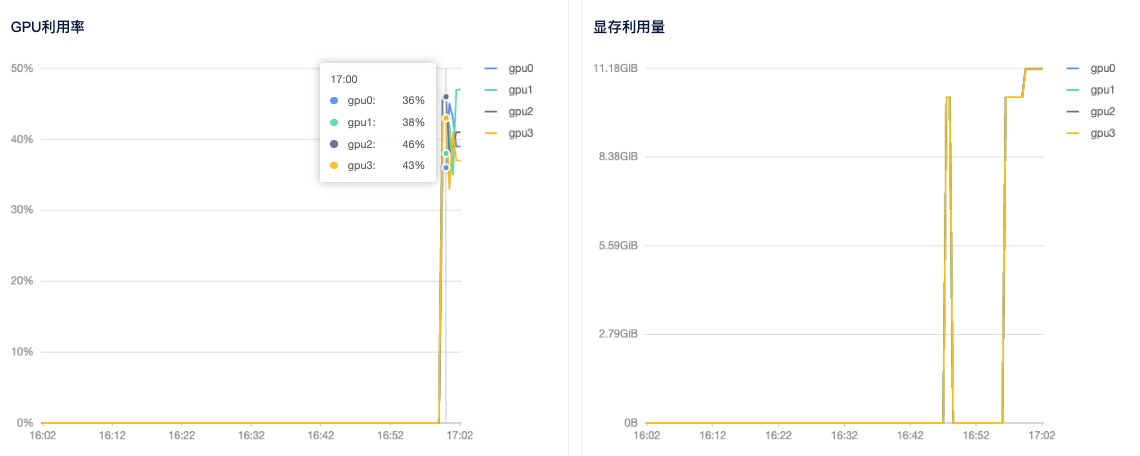
6)查看GPU使用情况: 租用界面点击详情按钮即可查看 GPU、CPU使用情况。

GPU 分布式使用教程之 Horovod
Horovod 是实现分布式机器学习的较佳实践之一,支持 Pytorch,TensorFlow,Keras,MXNet,采用 Ring-AllReduce 算法,在 GPU 较多时,算力的发挥能提升近一倍,且代码改动较小。使用镜像即可快速开启单机多卡/多机多卡分布式学习。
选择机器
- 单机多卡分布式:租用同个计算节点的多张卡即可。
- 多机多卡分布式: 点击直达分布式集群,在租用时,请选择带有如图所示图标的机器。没有这个图标的机器不支持加入分布式网络。
![]()
单机多卡
**1)租用机器:**单机多卡使用 Horovod 实现较简单。首先,您需要按正常流程租用GPU,主机市场筛选栏选择 支持分布式集群 筛选,然后选择自己需要的机器租用即可。如单节点 4 卡 K80,选择含有 Horovod 镜像,如Pytorch1.8.1-Horovod/TensorFlow 2.4-Horovod。
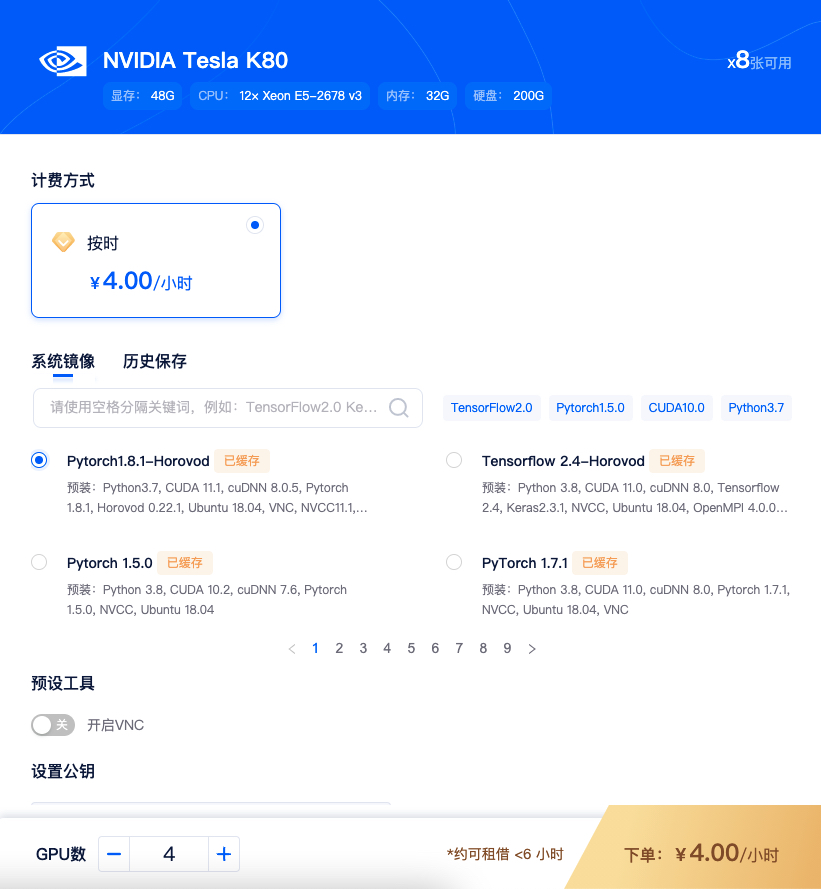
**2)运行代码:**进入运行脚本所在目录,输入命令行,如
shell复制代码# 进入项目目录 cd /mnt/test/multi-card/horovod # 安装依赖 pip install filelock # 运行代码 horovodrun -np 4 python test.py

即可实现单机多卡计算。-np 指定进程数,推荐设定为总GPU数。test.py 可使用官方范例。普通的脚本如果要使用 Hovorod,修改方法可参考第三部分:脚本修改
多机多卡
1)租用机器: 首先,您需要按正常流程租用GPU,主机市场筛选栏选择 支持分布式集群 筛选,然后选择自己需要的机器租用即可。如两个计算节点,每节点各 2 卡 A2000,共计 4 卡。选择相应的 Horovod 镜像,如Pytorch1.8.1-Horovod/TensorFlow 2.4-Horovod。
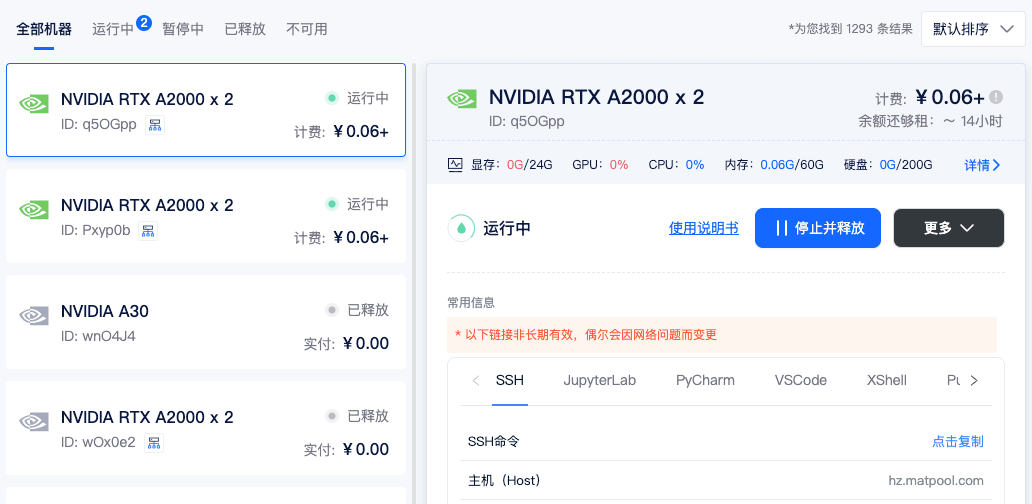
2)创建集群: 进入 【个人中心】 — 【我的租用】 — 【分布式集群】。
点击【添加集群】可以创建一个集群。如果你和我一样,主要用来跑深度学习项目,可以将集群免费升级为深度学习集群。点击这里查看相关说明
3)添加机器: 点击集群页面添加机器按钮,勾选要加入集群的机器,点击确定,即可将租用机器添加到集群。
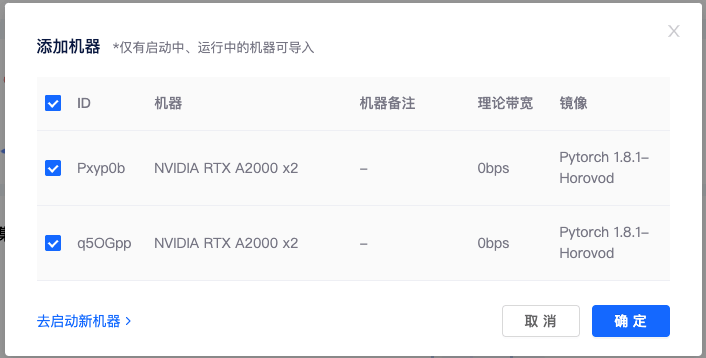
添加机器成功后,系统会给每个节点分配集群 IP,当状态为已连接时,代表机器间可相互通信。这里我们还需要设置一个 master 节点,设置后会自动进行以下操作:
- 所有节点注册网卡的环境变量:NCCL_SOCKET_IFNAME、GLOO_IFACE
- 配置 master 节点到其它节点的SSH公钥登录
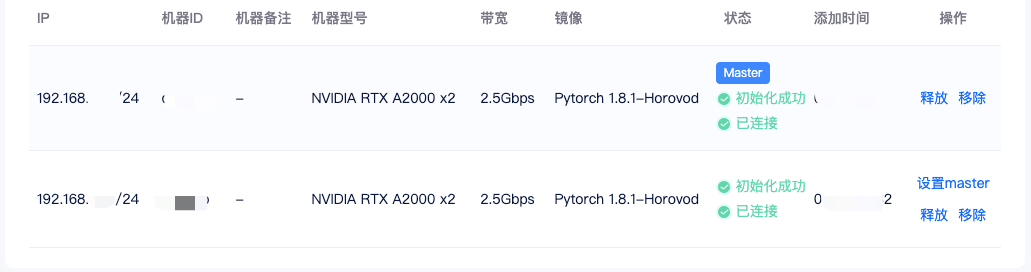
**4)运行代码:**进入项目代码目录,只需要在 master 运行下面命令即可:
shell复制代码# 进入项目目录 cd /mnt/test/multi-card/horovod # 安装依赖 pip install filelock # 只需在 master 节点运行 horovodrun -np 4 -H 192.168.1.29:2,192.168.1.30:2 --network-interface "192.168.1.29/24,192.168.1.30/24" python test.py
参数说明
- np:GPU显卡总数,比如我现在租用2台2卡机器总共就是4张显卡;
- H:指定各计算节点所运行卡数,格式为 IP:GPU数,多个节点之间逗号隔开,本机的信息也需要配置,所有节点都需要写入。例如 192.168.1.29:2 代表 IP 为 192.168.1.29,机器上有 2 张显卡;
- network-interface:指定各计算节点的 IP,需要与 H 的参数对应。
5)查看GPU使用情况: 租用界面点击详情按钮即可查看 GPU、CPU使用情况。
脚本修改
Horovod 对各模块进行了包裹,使用方便,但仍需对代码进行修改,逻辑和 Pytorch DDP 比较类似,官方流程如下:
python复制代码import torch import horovod.torch as hvd # Initialize Horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) torch.cuda.set_device(hvd.local_rank()) # Define dataset... train_dataset = ... # Partition dataset among workers using DistributedSampler train_sampler = torch.utils.data.distributed.DistributedSampler( train_dataset, num_replicas=hvd.size(), rank=hvd.rank()) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler) # Build model... model = ... model.cuda() optimizer = optim.SGD(model.parameters()) # Add Horovod Distributed Optimizer optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters()) # Broadcast parameters from rank 0 to all other processes. hvd.broadcast_parameters(model.state_dict(), root_rank=0) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{}]\tLoss: {}'.format( epoch, batch_idx * len(data), len(train_sampler), loss.item()))
更详细资料请参考官网